







Kompira Enterprise がチャネル、メールチャネル、API、kompira_sendevt モジュールなど、外部から受信したデータを解析して、ジョブフローの処理の起動を行ったり、処理条件を変える事があります。このような場合には受信した文字列を解析するために、文字列のパターンマッチングが必要となります。
※ 本稿は Kompira Enterprise 1.6系に準拠した画像を用いています。
動作確認環境
| ソフトウェア | バージョン |
|---|---|
| Kompira Enterprise | 1.4.10.post10 |
| OS | CentOS 6.10 |
または
| ソフトウェア | バージョン |
|---|---|
| Kompira Enterprise | 1.5.5.post7 |
| OS | CentOS 7.8.2003 |
または
| ソフトウェア | バージョン |
|---|---|
| Kompira Enterprise | 1.6.2.post4 |
| OS | CentOS 8.2.2004 |
または
| ソフトウェア | バージョン |
|---|---|
| Kompira Enterprise | 1.6.8 |
| OS | CentOS Stream 8 |
Kompira Enterprise でパターンマッチングを行う場合には、パターン型オブジェクトを利用します。パターンの種別は、’r’ (正規表現パターン)、’g’ (glob パターン) 、’e’ (完全一致パターン) の3種類があります。また、パターンマッチングを行う場合、大文字、小文字を区別しないモード (‘i’) を組み合わせることもできます。
パターン型オブジェクトを作成するには、組み込み関数 “pattern()” を利用します。
ptn_obj = pattern(pattern, typ='r', mode='')
引数:
■ pattern は、マッチングを行うパターンを指定します。
■ typ はパターンの種別を表し、”r” (正規表現パターン) 、”g” (glob パターン) 、”e” (完全一致パターン) のいずれかを指定することができます。
■ mode には、”i” を指定すると大文字小文字を区別しないパターン照合となります。指定しない場合は、大文字小文字を区別します。
戻り値:
■ パターン型オブジェクト (ptn_obj) を返します。
パターン型オブジェクトは、文字列 s とパターンとのマッチングを試みる match() メソッドを備えています。
ptn_obj.match(s)
引数:
■ s は、マッチング対象の文字列を指定します。
戻り値:
■ マッチした場合は true 、もしくはパターンが正規表現パターンの場合はマッチした情報を格納した辞書を返します。
■ マッチしなかった場合は false を返します。
続いて、ログファイルの行をサンプルにして、各マッチング種別の動きを見ていきましょう。
完全一致パターン
完全一致パターンは、対象の文字列とパターンで指定した文字列が一致するかを確認します。
対象の文字列とパターンで指定した文字列が一致する場合は true 、一致しない場合には false を返します。
| sequence = "[Wed Aug 30 09:44:40 2017] [warn] child process 13408 still did not exit, sending a SIGTERM" |
| ptn_1 = "[Wed Aug 30 09:44:40 2017] [warn] child process 13408 still did not exit, sending a SIGTERM" |
| ptn_2 = "[Wed Aug 30 09:44:40 2017] [warn] child process 13408 still did not exit, sending" |
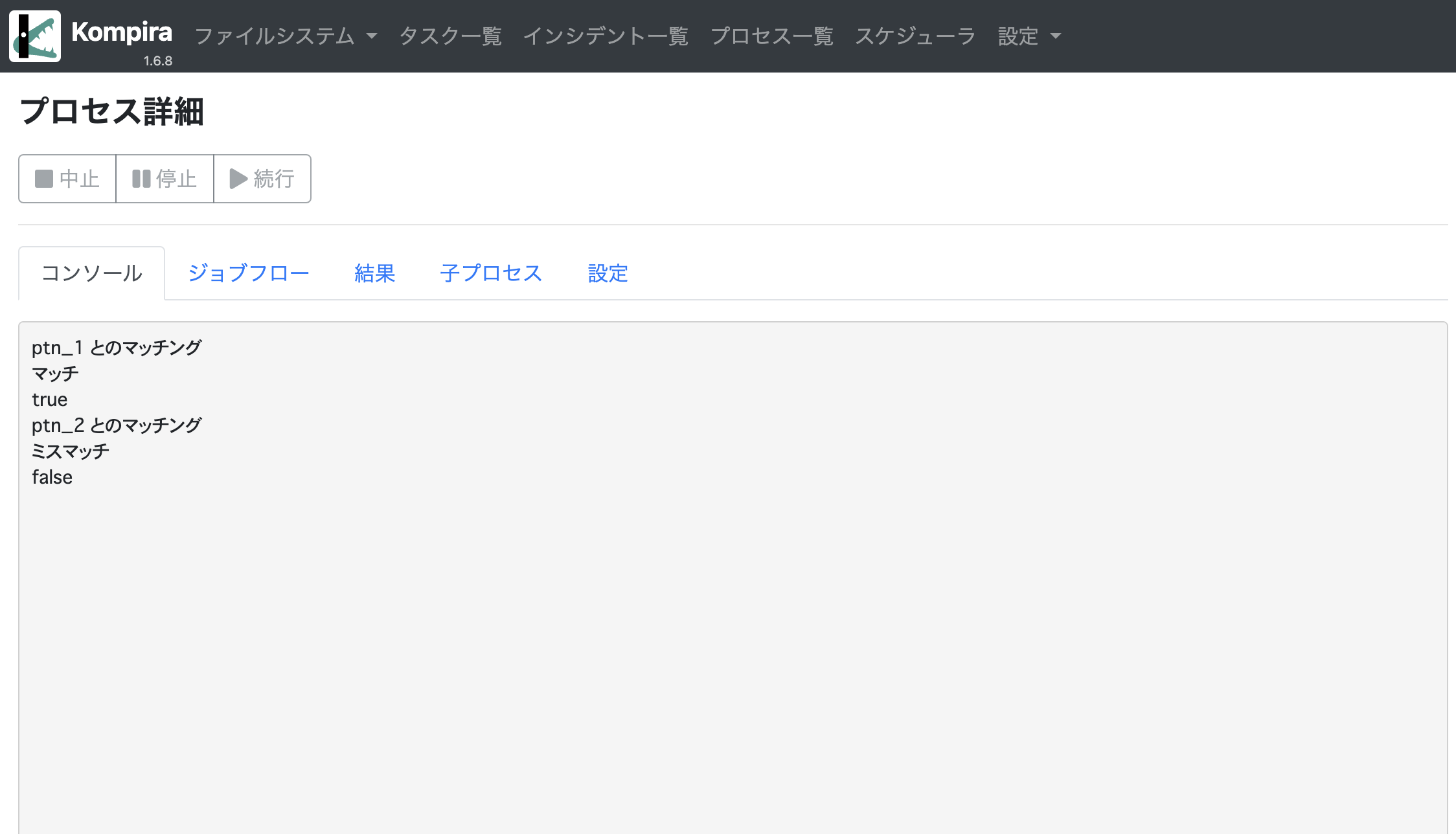
print("ptn_1 とのマッチング") ->
[match_rst = pattern(ptn_1, typ="e").match(sequence)] ->
{ if match_rst |
then:
print("マッチ")
else:
print("ミスマッチ")
} ->
print(match_rst) ->
print("ptn_2 とのマッチング") ->
[match_rst = pattern(ptn_2, typ="e").match(sequence)] ->
{ if match_rst |
then:
print("マッチ")
else:
print("ミスマッチ")
} ->
print(match_rst)
上記の場合、以下のように ptn_1 とのマッチング結果は true となり、ptn_2 とのマッチング結果は false となります。
完全一致パターンは、以下のように単純な文字列比較として記述することもできます。
| sequence = "[Wed Aug 30 09:44:40 2017] [warn] child process 13408 still did not exit, sending a SIGTERM" |
| ptn_1 = "[Wed Aug 30 09:44:40 2017] [warn] child process 13408 still did not exit, sending a SIGTERM" |
| ptn_2 = "[Wed Aug 30 09:44:40 2017] [warn] child process 13408 still did not exit, sending" |
print("ptn_1 とのマッチング") ->
{ if sequence == ptn_1 |
then:
print("マッチ")
else:
print("ミスマッチ")
} ->
print("ptn_2 とのマッチング") ->
{ if sequence == ptn_2 |
then:
print("マッチ")
else:
print("ミスマッチ")
}
glob パターン
glob パターンでは、Unix のシェル形式のワイルドカードを用いることができ、以下の特別な文字に対応しています。
■ 「*」: すべての文字にマッチ
■ 「?」: 任意の一文字にマッチ
■ 「[seq] 」: seq にある任意の文字にマッチ
■ 「[!seq]」: seq にない任意の文字にマッチ
“*” 、”?” 、”[” などの特殊文字をエスケープしたい場合は、[*] 、[?] 、[[] のように [] で囲って記述してください。
ログに “[warn]” という文字列が含まれているかを判別する処理は、以下のように (“*[[]warn[]]*”) 、glob パターンを用いて記述することができます。
match() は一致する場合は true 、一致しない場合には false を返します。
| sequence = "[Wed Aug 30 09:44:40 2017] [warn] child process 13408 still did not exit, sending a SIGTERM" |
| ptn_1 = "*[[]warn[]]*" |
| ptn_2 = "*[[]warn []]*" |
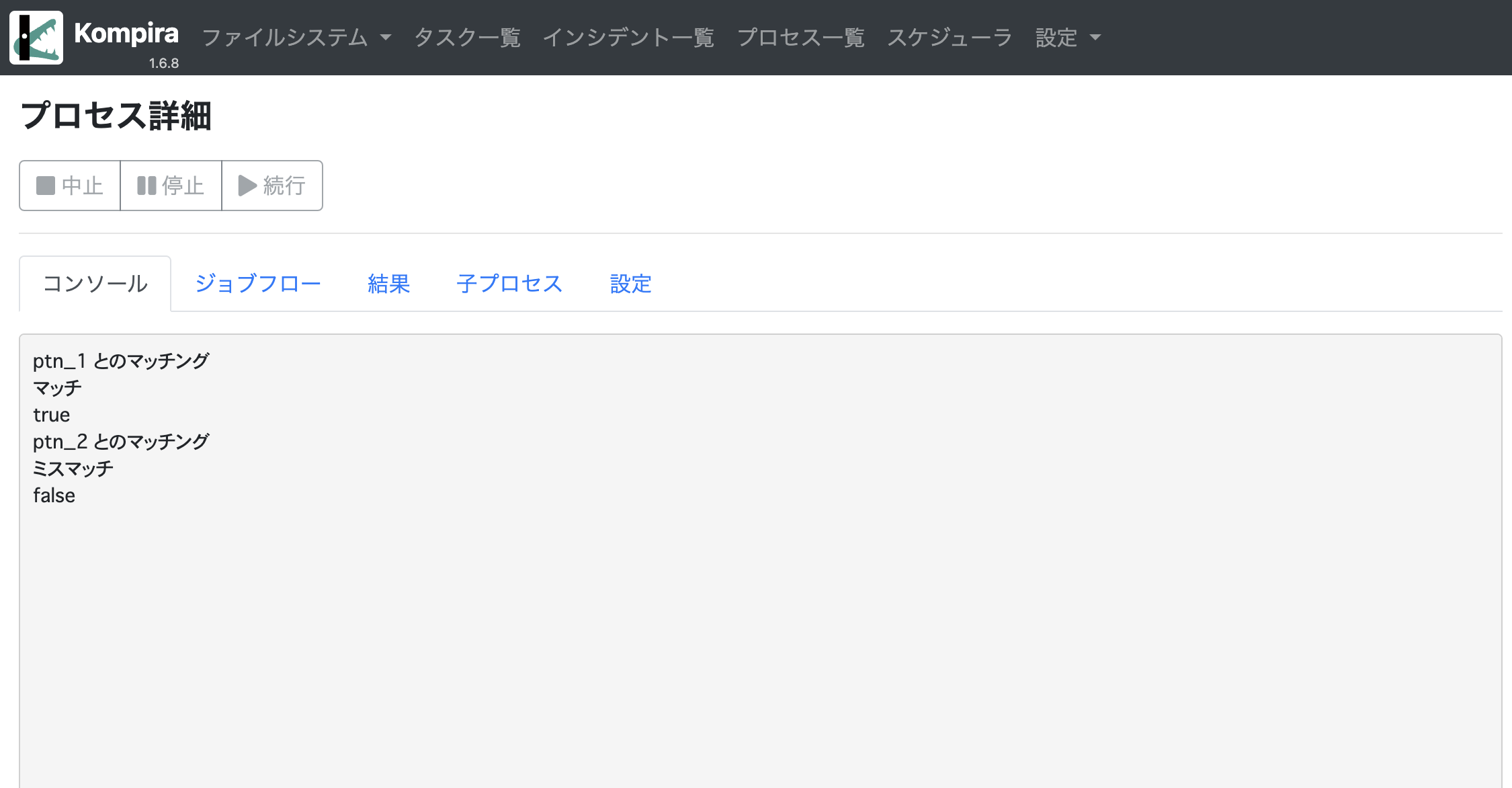
print("ptn_1 とのマッチング") ->
[match_rst = pattern(ptn_1, typ="g").match(sequence)] ->
{ if match_rst |
then:
print("マッチ")
else:
print("ミスマッチ")
} ->
print(match_rst) ->
print("ptn_2 とのマッチング") ->
[match_rst = pattern(ptn_2, typ="g").match(sequence)] ->
{ if match_rst |
then:
print("マッチ")
else:
print("ミスマッチ")
} ->
print(match_rst)
上記の場合、以下のように ptn_1 とのマッチング結果は true となり、ptn_2 とのマッチング結果は false となります。
glob パターンは、比較的単純なマッチングにおいて有効な方法です。
正規表現パターン
正規表現パターンは、プログラミング言語 Python の re モジュールの正規表現に準じています。
また、match() メソッドの応答は、完全一致パターンや glob パターンと異なり、マッチした場合は、マッチした情報を格納した辞書を返します。() でくくったグループごとに、マッチした文字列を返します。マッチしない場合は false を返します。
以下の処理では、ログ取得の日時、ログレベル、メッセージの3つの情報にマッチさせて、それぞれ個別に表示します。
マッチした文字列は戻り値内の groups に格納されます。マッチしない場合は、false が返ります。
特殊文字をエスケープしたい場合は、\ をエスケープしたい文字の直前に記述します。
| sequence = "[Wed Aug 30 09:44:40 2017] [warn] child process 13408 still did not exit, sending a SIGTERM" |
| ptn_1 = "\[(.+)\] \[(warn|error)\] (.+)" |
| ptn_2 = "\[(.+)\] \[(warn_|eror)\] (.+)" |
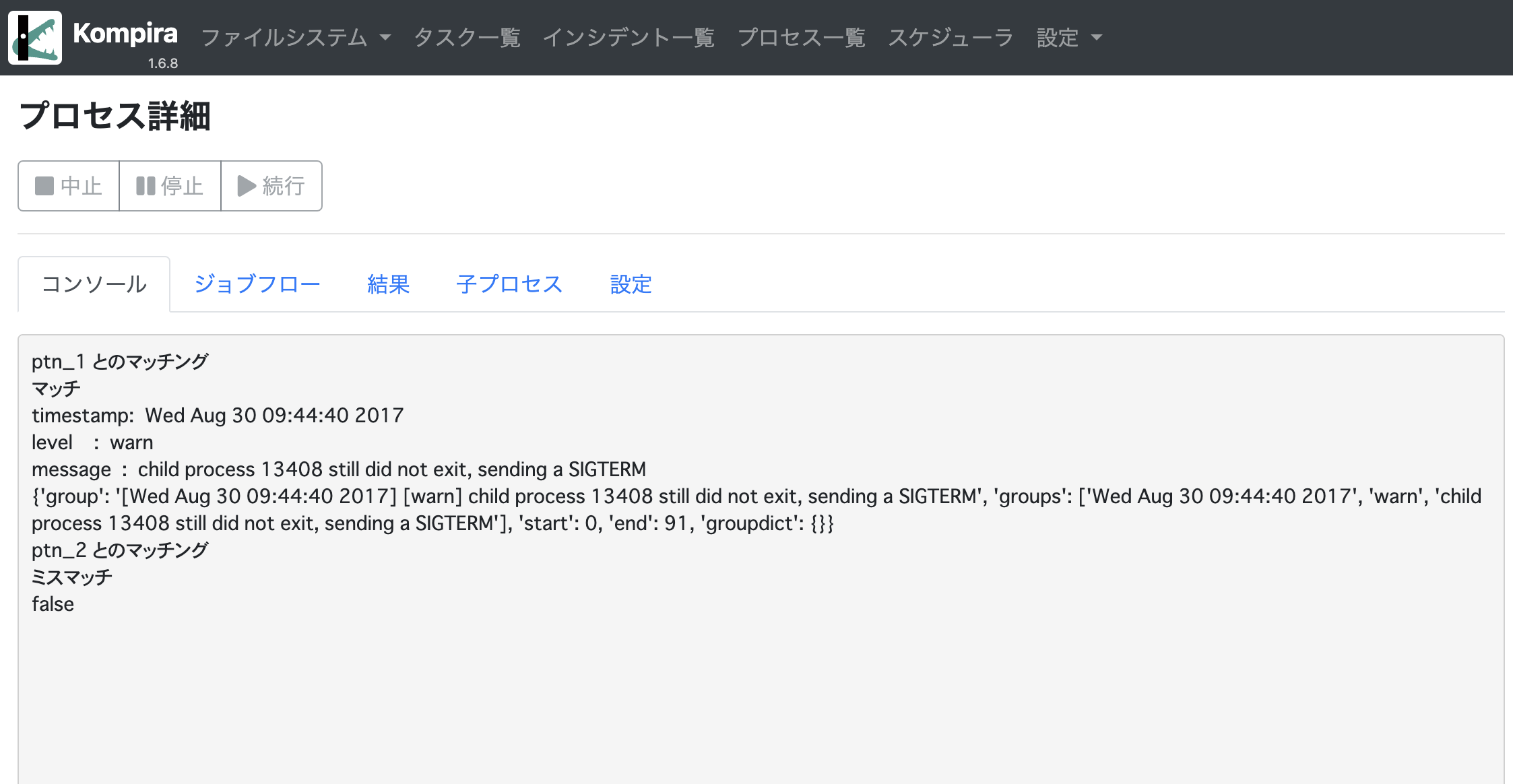
print("ptn_1 とのマッチング") ->
# 正規表現によるマッチ
[match_rst = pattern(ptn_1, typ="r").match(sequence)] ->
{ if match_rst |
then:
print("マッチ") ->
print("timestamp: ", match_rst.groups[0]) ->
print("level : ", match_rst.groups[1]) ->
print("message : ", match_rst.groups[2])
else:
print("ミスマッチ")
} ->
print(match_rst) ->
print("ptn_2 とのマッチング") ->
# 正規表現によるマッチ
[match_rst = pattern(ptn_2, typ="r").match(sequence)] ->
{ if match_rst |
then:
print("マッチ") ->
print("timestamp: ", match_rst.groups[0]) ->
print("level : ", match_rst.groups[1]) ->
print("message : ", match_rst.groups[2])
else:
print("ミスマッチ")
} ->
print(match_rst)
上記の場合、以下のように ptn_1 とのマッチング結果は true となり辞書型が与えられ、ptn_2 とのマッチング結果は false となります。
正規表現でのマッチングは、glob パターンより複雑ですが、より細かい条件設定を行うことが出来ます。
パターンリテラル
これまではマッチングパターンのオブジェクトを作成するために pattern() 関数を利用してきました。
Kompira Enterprise では、pattern() の代わりに、パターンリテラルを用いる事も出来ます。
パターンリテラルは、パターンの種別を表す ‘e’ 、‘g’ 、‘r’ のいずれかの文字に引き続き、一重引用符 (‘) 、もしくは、二重引用符 (”) で囲まれた0個以上の文字 (パターン文字列) で表現されます。
上記の「正規表現パターン」のジョブフローは、パターンリテラルを用いると以下のように記述することができます。
| sequence = "[Wed Aug 30 09:44:40 2017] [warn] child process 13408 still did not exit, sending a SIGTERM" |
print("ptn_1 とのマッチング") ->
# 正規表現のパターンリテラルによるマッチ
[match_rst = r"\[(.+)\] \[(warn|error)\] (.+)".match(sequence)] ->
{ if match_rst |
then:
print("マッチ") ->
print("timestamp: ", match_rst.groups[0]) ->
print("level : ", match_rst.groups[1]) ->
print("message : ", match_rst.groups[2])
else:
print("ミスマッチ")
} ->
print(match_rst) ->
print("ptn_2 とのマッチング") ->
# 正規表現のパターンリテラルによるマッチ
[match_rst = r"\[(.+)\] \[(warn_|error)\] (.+)".match(sequence)] ->
{ if match_rst |
then:
print("マッチ") ->
print("timestamp: ", match_rst.groups[0]) ->
print("level : ", match_rst.groups[1]) ->
print("message : ", match_rst.groups[2])
else:
print("ミスマッチ")
} ->
print(match_rst)
実行結果は pattern() を使った場合と同様になります。正規表現以外にも完全一致パターン、 glob パターンの場合も同様に記述する事が出来ます。
正規表現パターンの名前付きグループ
正規表現を用いたパターンを使って値を参照しようとする場合、値は groups という配列に格納されているため、パターン中の順序を意識する必要があります。
Kompira Enterprise では、各パターンのグループに明示的に名前をつけることで、名前を用いて値を参照することができます。
名前つきグループのための構文は、固有拡張の一つ「(?P…)」を使います。
上記の「パターンリテラル」のジョブフローを以下のように書き換えることで、名前付きグループを用いることができます。
| sequence = "[Wed Aug 30 09:44:40 2017] [warn] child process 13408 still did not exit, sending a SIGTERM" |
# 正規表現によるマッチ
[match_rst = r"\[(?P<timestamp>.+)\] \[(?P<level>warn|error)\] (?P<message>.+)".match(sequence)] ->
{ if match_rst |
then:
print("マッチ") ->
print("timestamp:" , match_rst.groupdict.timestamp) ->
print("level :" , match_rst.groupdict.level) ->
print("message :" , match_rst.groupdict.message)
else:
print("ミスマッチ")
} ->
print(match_rst)
それぞれの要素に “timestamp” 、”level” 、”message” という名前を付けています。
出力は、以下のようになります。
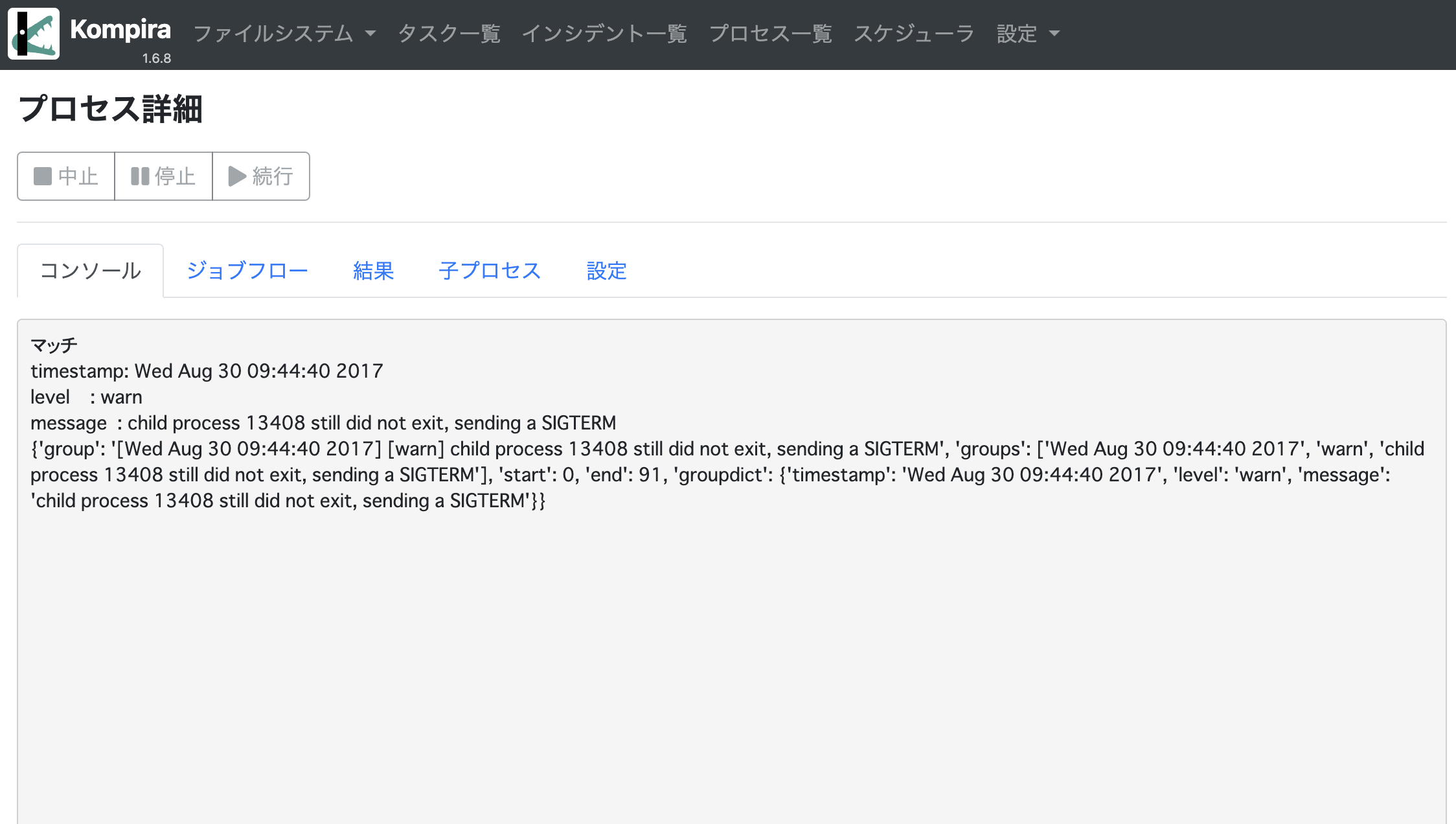
マッチさせた文字列は、groupdict という辞書に指定した名前をキーにして格納されていますので、上記の例では “match_rst.groupdict.timestamp” のように参照できます。
このようにしてパターン型オブジェクトやパターンリテラルを用いることで、文字列のパターンマッチングを行うことができます。これにより、文字列から必要な情報を取得したりするなどの、文字列の解析処理を行うことができます。